


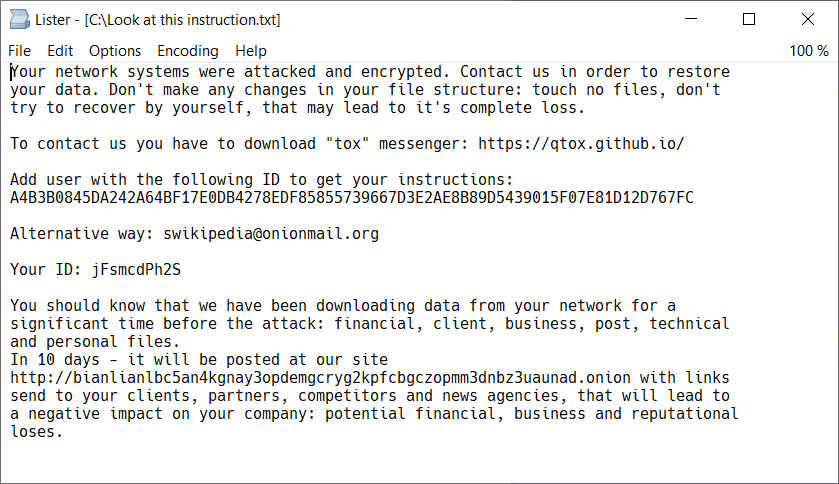
日前,安全公司 Avast 公布了免费的变脸(BianLian)勒索软件解密器。
变脸勒索软件是在2022年8月出现的,主要针对媒体、娱乐、制造和医疗保健行业的目标,它用 Go 语言开发,硬编码了1013种文件扩展名,感染之后它会搜索系统中的这些扩展名用 AES-256进行加密,加密后的文件扩展名为 bianlian,然后留下一份勒索通知。Avast 公布的解密器主要针对现有的变种,如果出现变脸勒索软件的新变种,它可能无法解密。[阅读原文]
文章原文链接:https://www.anquanke.com/post/id/285601

